1. iter 함수
- 우리는 보통 하나 이상의 값을 저장하거나 저장된 값들을 하나씩 꺼내 볼 때, for 루프를 이용함

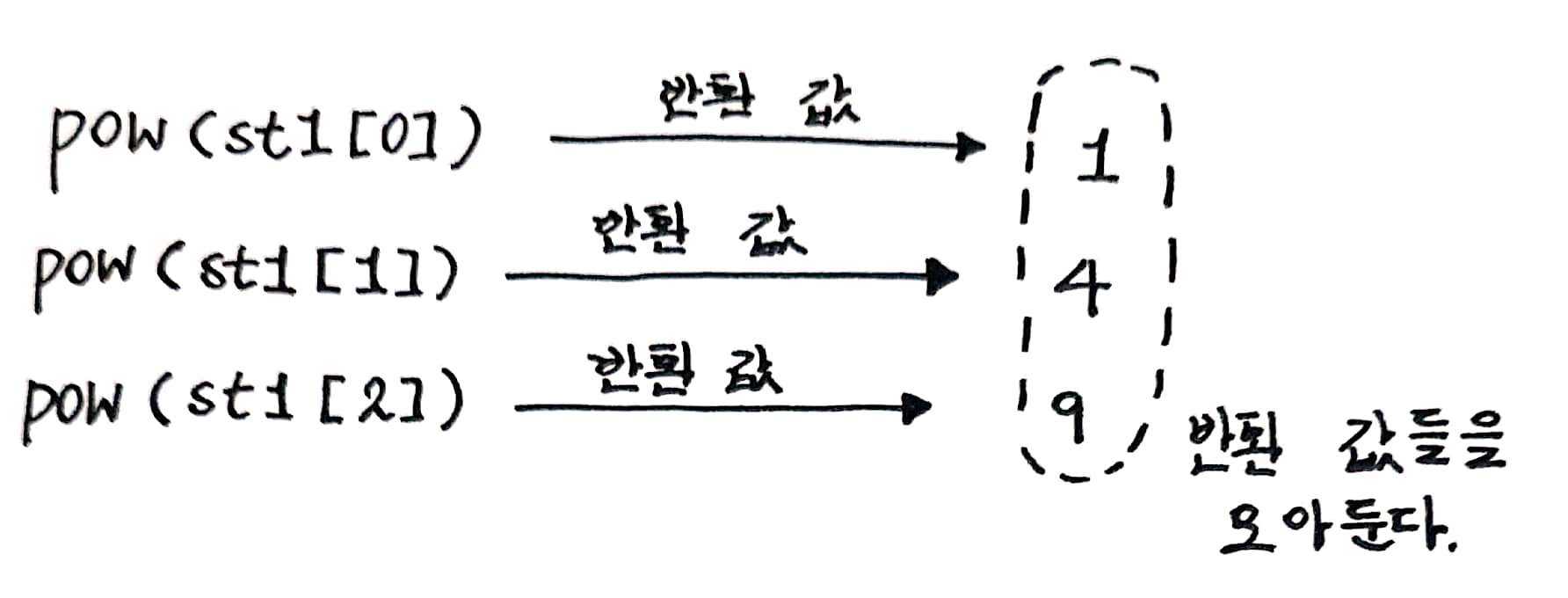
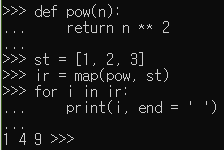
- ds에 저장된 것 하나씩 꺼내서 출력하는 for 루프

- iter라는 함수를 호출하면서 리스트를 전달했음
- iter함수는 객체를 생성해서 반환 = 리스트에서 값을 꺼내는 기능을 제공
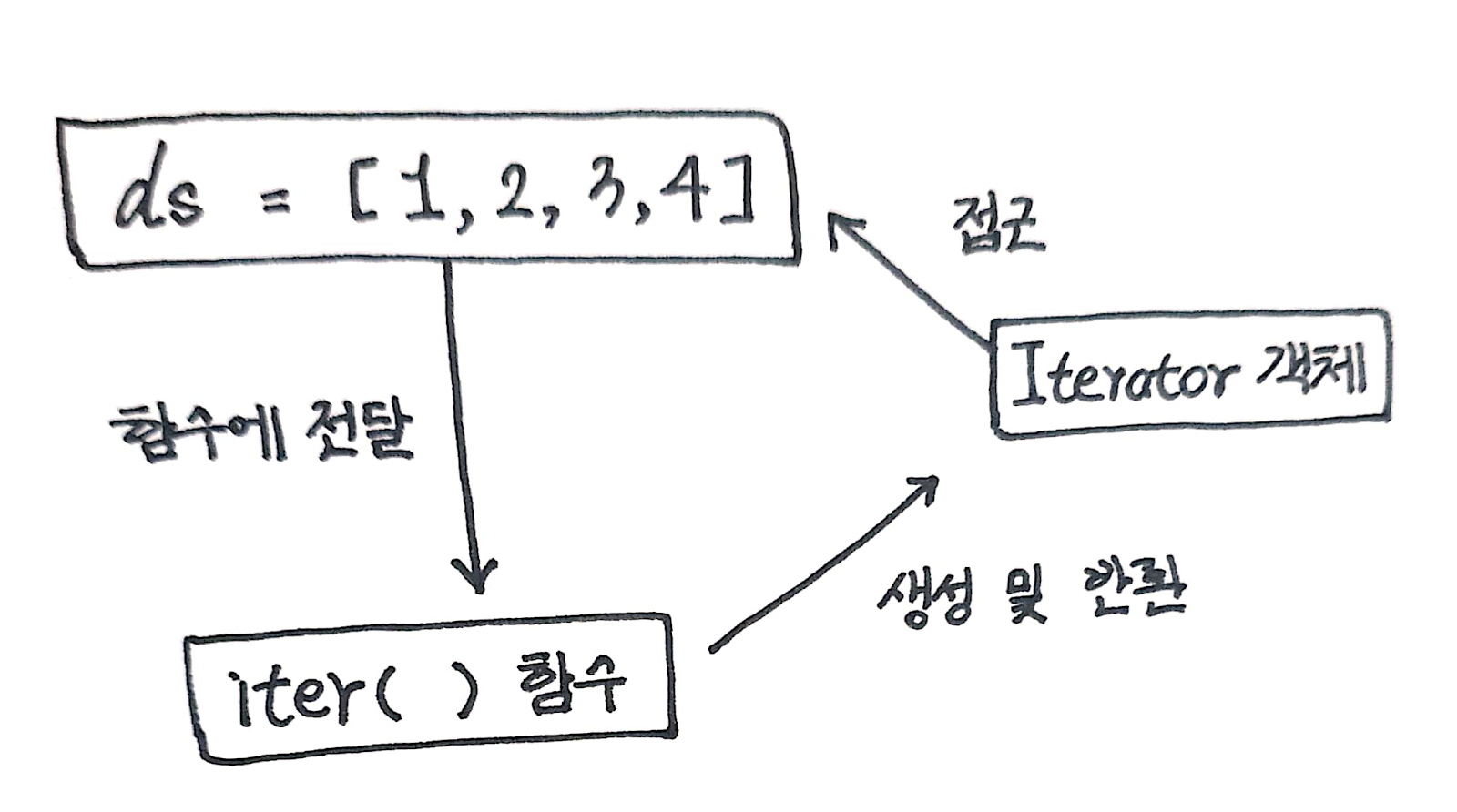
- ir = iter(ds) : 리스트 ds를 전달하면서 iter 함수를 호출하였음
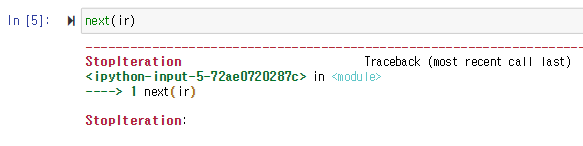
- 이미 마지막 값을 얻었음에도 불구하고 다시 next 함수를 호출하면 위와 같이 예외가 발생함

- 마지막 값을 얻고 다시 처음부터 값을 얻으려면 iterator 객체를 다시 불러오면 됨
- 이런 방식으로 값을 꺼내게 되면, 원하는 시기에 하나씩 값을 꺼낼 수 있음
- 사탕으로 예를 들자면, 하루에 모든 사탕을 다 꺼내 먹을 수 있지만, 마지막 사탕은 남겨뒀다가 내일 먹을수도 있음
- 즉, 꺼내는 방법과 꺼낸 값을 처리하는 방법에 있어서도 유연성이 생김
2. Iterable 객체와 Iterator 객체의 구분
| Iterable 객체 | - iter 함수에 인자로 전달 가능한 객체 - iterator 객체를 얻을 수 있는 리스트와 같은 객체 |
| Iterator 객체 | - iter 함수가 생성해서 반환하는 객체 |
- 어떤 객체가 iterator/iterable 객체인지 확인하는 방법 = iter 함수에 전달해 보는 것
- 전달 결과로 오류 없이 iterator 객체가 만들어진다면, 이것은 iterable 객체인 것
🡺 iterable 객체를 대상으로 iter 함수를 호출해서 iterator 객체를 만듦
🡺 iterator 객체를 생성할 수 있는 대상이 되는 것이 iterable 객체임
3. 스페셜 메소드

- 위와 같은 방식으로 작성하면, iter 함수와 next 함수는 객체에 속하지 않는 함수처럼 보임
- 그러나 실제 함수 호출 형태는 아래와 같음
| >>> ds = [1, 2, 3] >>> ir = ds.__ite.r__( ) >>> ir.__next__( ) 1 >>> ir.__next__( ) 2 |
🡺 리스트의 __iter__ 메소드 호출을 통해서 iterator 객체를 얻게 됨
🡺 iterator 객체의 __next__ 메소드 호출을 통해서 값을 하나 씩 얻게 됨
- 이렇게 직접 호출하지 않아도 파이썬 인터프리터에 의해서 호출되는 메소드를 ‘스페셜 메소드(special method)라고 부름
: 객체 생성 시 자동으로 호출되는 __init__ 메소드도 스페셜 메소드임
4. Iterable 객체의 종류와 확인 방법

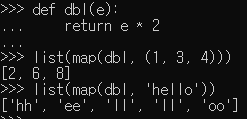
- 튜플로도 iterator 객체를 얻을 수 있음

- 문자열을 대상으로도 iterator 객체를 얻을 수 있음

- dir 함수를 호출해서 __iter__ 메소드가 존재하는지 확인하는 방법으로도 iterable 객체인지 아닌지 판단할 수 있음

- 리스트에 __iter__함수가 있는지 묻는 것으로도 판단할 수 있음
5. for 루프와 Iterable 객체

- for 루프도 값을 하나씩 꺼내기 위해 iterable 객체를 생성해서 도움을 받음

- iterator 객체를 얻음
- iterator 객체를 통해서 값을 하나씩 꺼낸 뒤, 더 이상 꺼낼 것이 없으면 루프를 탈출하도록 함
- 따라서, for 루프의 반복 대상은 반드시 iterable 객체여야만 함
- iter 함수의 인자로 전달이 가능한 iterable 객체여야 함
- 그래서 iterable 객체인 리스트, 튜플, 문자열은 for 루프의 반복 대상이 될 수 있는 것
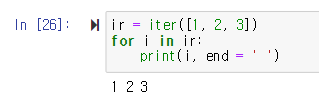
- ir에 저장되는 것은 iterator 객체
- for 루프에 iterator 객체를 가져다 두었음
- 이처럼, for 루프에 iterable 객체가 아닌 iterator 객체를 두어도 정상적으로 작동함

- 그 이유는 위와 같이 iter 함수에 iterator 객체를 전달하면 전달된 iterator 객체를 그대로 되돌려주기 때문임
🡺 iterable 객체와 iterator 객체 모두 for 루프의 반복 대상이 될 수 있다.
🡺 iterable 객체가 와야 하는 위치에는 iterator 객체가 올 수 있다.
'윤성우의 열혈 파이썬 (중급)' 카테고리의 다른 글
| Story 11. 튜플의 패킹과 언패킹 (0) | 2021.07.18 |
|---|---|
| Story 10. 제너레이터 표현식 (0) | 2021.07.16 |
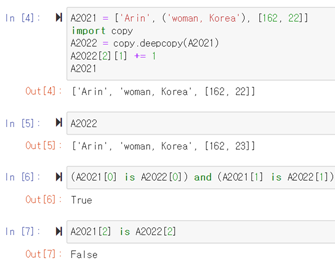
| Story 03. 깊은 복사와 얕은 복사 (0) | 2021.07.15 |
| Story 06. 객체처럼 다뤄지는 함수 그리고 람다 (0) | 2021.07.15 |
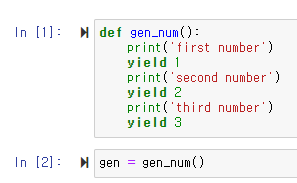
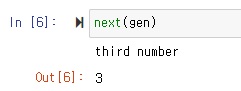
| Story 09. 제너레이터 함수 (0) | 2021.07.15 |