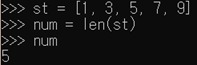
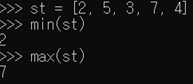
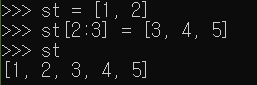- len(s) : 리스트 s의 길이(저장된 값의 수) 반환 - min(s) : 리스트 s에 저장된 값 중에서 가장 작은 값 반환 - max(s) : 리스트 s에 저장된 값 중에서 가장 큰 값 반환
- 가장 작은 값과 가장 큰 값 반환 가능
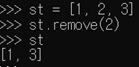
- 뿐만 아니라 제거할 수도 있음
- s.append(x) : 리스트 s의 끝에 x를 추가 - s.extend(t) : 리스트의 s의 끝에 리스트 t의 내용 전부를 추가 - s.clear() : 리스트 s의 내용물 전부 삭제 - s.insert(i,x) : s[i]에 x를 저장 - s.pop(i) : s[i]를 반환 및 삭제 - s.remove(x) : 리스트 s에서 제일 앞에 등장하는 x를 하나만 삭제 - s.count(x) : 리스트 s에 등장하는 x의 개수 반환 - s.index(x) : 리스트 s에 처음 등장하는 x의 인덱스 값 반환
- 하나만 추가할 땐 append, 두 개 이상을 추가할 땐 extend 사용
- 삽입과 삭제
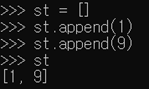
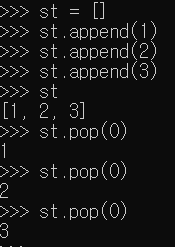
- 빈 리스트 하나 만들고 거기에 1, 9 추가
- pop과 remove의 차이점
- pop은 삭제할 때 위치를 지정하는 반면, remove는 삭제할 값을 명시함
- st.pop(0) : 인덱스 값 0의 위치에 저장된 데이터 삭제
- st.remove(5) : 리스트에서 5를 삭제
<연습문제 06-1>
▶ 문제 1. 다음은 빈 리스트를 만들어서 그 안에 1, 2, 3을 넣었다가 넣은 순서대로 꺼내는 코드의 실행 흐름이다. 실행 흐름이 완성되도록 빈칸에 문장들을 채워넣자.
▶ 문제 2. 위의 문제 1에서는 리스트에 다음 순서대로 값을 저장하고 꺼냈다. - 저장 순서 : 1, 2, 3 - 꺼낸 순서 : 1, 2, 3
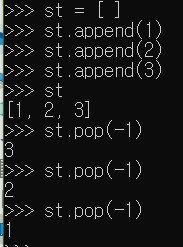
이번에는 다음 순서대로 값을 저장하고 꺼내도록 코드를 작성해보자. - 저장 순서 : 1, 2, 3 - 꺼낸 순서 : 3, 2, 1
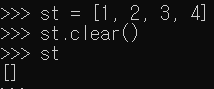
▶ 문제 3. 앞서 본문에서 리스트에 저장된 내용 전부를 삭제하는 clear 함수를 소개하였다. 그런데, 이렇듯 리스트에 저장된 값을 싹 비우는 방법을 앞서 5장에서도 소개한 바 있다. 슬라이싱 연산을 이용하는 방법인데, 이 방법을 이용하는 형태로 위의 코드를 수정해보자.
▶ 문제 4. 빈 리스트를 만들어서 그 안에 1부터 10까지 넣었다가, 다시 1부터 10까지 꺼내는(삭제하는) 코드를 만들어보자. 단 이번에는 넣고 꺼내야 할 값이 많으니 for 루프를 이용하는 형태로 코드를 작성해보자.
▶ 문제 5. 빈 리스트를 만들어서 그 안에 1부터 10까지 넣었다가, 다시 10부터 1까지 꺼내는(삭제하는) 코드를 만들어보자. 이번에도 문제 4와 마찬가지로 for 루프를 이용하자.
▶ 문제 6. 다음은 하나의 리스트에 다른 리스트의 값 전부를 추가하는 코드이다.
>>> st = [1, 2] >>> st.extend([3, 4, 5]) >>> st [1, 2, 3, 4, 5]
위의 예에서는 extend 함수를 사용했는데, 이를 슬라이싱 연산을 이용하는 형태로 수정해보자. 다음 리스트에는 세 번째 값이 없다.
st = [1, 2]
그러나 다른 리스트이 값 전부를 추가할 때에는 세 번째 값이 있다고 가정하고 슬라이싱 연산을 전환하면 된다. 즉 세 번째 값을 리스트 [3, 4, 5]의 내용으로 교체하는 슬라이싱 연산문을 작성하면 된다.
[6-2. 두 가지 유형의 함수가 갖는 특징들]
1) 두 가지 유형의 함수가 갖는 특징들
- len(s) : 리스트 s의 길이(s에 저장된 값의 수) 반환
- min(s) : 리스트 s에 저장된 값 중에서 가장 작은 값 반환
- max(s) : 리스트 s에 저장된 값 중에서 가장 큰 값 반환
- 문자열의 길이는?
- 알파벳 순서 중 가장 앞에 있는 문자는?
- 알파벳 순서 중 가장 뒤에 있는 문자는?
[6-3. 문자열과 함수들]
1) 문자열과 함수들
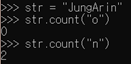
- s.count(sub) : 문자열 s에 sub가 등장하는 횟수 반환 - s.lower( ) : 문자열 s의 내용을 전부 소문자로 바꾼 문자열 변환 - s.upper( ) : 문자열 s의 내용을 전부 대문자로 바꾼 문자열 변환 - s.lstrip( ) : 문자열 s의 앞에 위치한 공백을 모두 제거한 문자열 반환 - s.rstrip( ) : 문자열 s의 뒤에 위치한 공백을 모두 제거한 문자열 반환 - s.strip( ) : 문자열 s의 앞과 뒤에 위치한 공백을 모두 제거한 문자열 반환 - s.replace(old, new) : 문자열 s의 old를 new로 교체한 문자열 반환 - s.split( ) : 문자열 s를 공백을 기준으로 나눠서 리스트에 담아서 반환
- o가 몇 번 등장하는지?
- n이 몇 번 등장하는지?
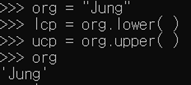
- lcp : 모든 문자를 소문자로 바꿔서 변환하라
- ucp : 모든 문자를 대문자로 바꿔서 변환
- org : 원본은 그대로 존재
<연습문제 06-2>
▶ 문제 1. 문자열 "The Espresso Spirit"을 다음과 같이 선언하자. >>> str = "The Espresso Spirit" 그리고 한 번은 모두 대문자로 바꿔서 출력하고, 또 한 번은 모두 소문자로 바꿔서 출력해보자. 그리고 마지막에 원본 그대로 출력을 한 번 더 하자.
▶ 문제 2. 우리나라의 주민 번호는 다음과 같은 구조이다. '070609-2011xxx' '090716-1012xxx' 이 중에서 앞의 여섯 자리는 생년월일 정보이다. 따라서 문자열로 표현된 위의 주민등록번호에서 생년 월일 정보만 꺼내서 출력하고자 하니, 이러한 기능을 제공하는 함수를 만들어보자. 예를 들어서 함수의 이름이 birth_only라 한다.